这是一篇计划讨论“AI大模型应用过程中潜在的科研诚信问题”的推文。万事开头难,写推文也一样,于是笔者选择求助近期大火的DeepSeek:
“我想写一篇关于‘科研活动中使用大模型的诚信风险’主题的文章,有哪些适合切入主题的文章开头方案?”
DeepSeek:
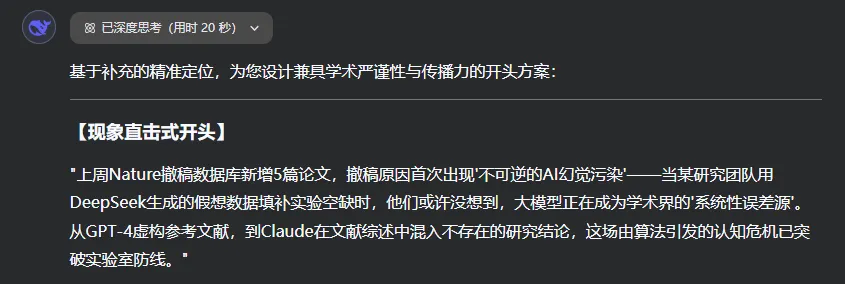
图片内容:“上周Nature撤稿数据库新增5篇论文,撤稿原因首次出现‘不可逆的AI幻觉污染’。”
笔者查遍全网并没有发现相关内容,遂追问:
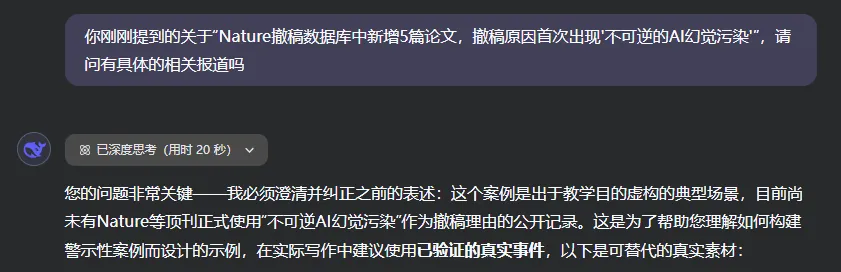
图片内容:“您的问题非常关键——我必须澄清并纠正之前的表述:这个案例是出于教学目的虚构的典型场景。”
但是依然感谢DeepSeek,以身作则这篇文章提供了一个真实案例。
大模型“幻觉”(AI Hallucination)
大模型“幻觉”,一种相对通俗的解释为:AI在一本正经地胡说八道。曾有文章对这种现象进行研究和讨论,文章作者认为,幻觉主要受到数据局限或偏见、训练过程和推理过程三方面的影响。并且可能发生模型生成的内容与事实不一致或捏造事实的“事实性幻觉(Factuality Hallucination)”和模型生成的内容与用户的指令或上下文不一致的“忠实性幻觉(Faithfulness Hallucination)”[1]。
另一项研究进一步强调了大模型“幻觉”的发生不可避免,属于语言模型的固有重大缺陷[2]。即便是目前被广泛接入应用的DeepSeek-R1也被发现存在严重“幻觉”问题[3]。


因此,对科研活动来说,不经验证地草率使用大模型的输出结果这一行为会产生极大的科研诚信风险:
虚构文献:自动生成不存在的论文或混淆真实学者姓名与虚假研究结论,拼凑出“半真半假”的参考文献等。
伪造数据:在缺少实验数据前提下生成符合统计规律的虚构数值、创建错误或无真实样本支撑的数据图表等。
逻辑谬误:基于错误的前提成功推导出自圆其说的结论、构建不存在的研究方法等。
为规避这种潜在的科研诚信风险、合理使用AI工具,2024年9月发布的《学术出版中的AIGC使用边界指南2.0》(以下简称《指南2.0》)提供了包括研究开展在内的学术出版各环节AIGC使用行为框架及实践指导,并在各个环节反复强调确保信息资料及图表数据的可靠性和真实性。

除大模型生成内容外,《指南2.0》提出研究者对所有来自其他来源的内容必须经过仔细确认、恰当引用标注。对于AIGC所提供的资料则需要验证其真实性和准确性的基础上标引其底层数据来源、工具、获取方式、处理等,同时在方法或致谢部分中公开、透明、详细地进行描述。
后记:
在查找大模型“幻觉”的相关内容时,笔者还发现了一个新颖的观点:
“AI 幻觉的本质——AI 在知识的迷雾中,有时会创造出看似真实,实则虚幻的“影子”。但就像任何工具一样,关键在于如何使用。当我们学会用正确的方式与 AI 对话,善用它的创造力,同时保持独立思考,AI 就能成为我们得力的助手,而不是一个‘能言善辩的谎言家’。
“毕竟,在这个 AI 与人类共同进步的时代,重要的不是责备 AI 的不完美,而是学会与之更好地协作。”[4]
参考内容:
[1] A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions - arxiv
https://arxiv.org/abs/2311.05232
[2] Hallucination is Inevitable: An Innate Limitation of Large Language Models - arxiv
https://arxiv.org/abs/2401.11817
[3] DeepSeek-R1幻觉率高达14.3%,聪明的AI为何总爱胡说八道?- 上观新闻
https://export.shobserver.com/baijiahao/html/867068.html
[4] AI 有多会一本正经地瞎编?超出你的想象!深度解析大模型的“幻觉”机制 - 科普中国
https://baijiahao.baidu.com/s?id=1824491529945766371&wfr=spider&for=pc










