每到毕业季,有关毕业论文的讨论总是层出不穷,大学生在终于跨过“AI乱编文献”的雷区进入论文检测环节之际,惊觉:怎么我也成“人机”了?

面对自己辛辛苦苦写的论文被判定高AI率,网友在恼火之际也开始对各家AI检测工具进行测试:《滕王阁序》喜提100%AI生成认证;朱自清的名篇《荷塘月色》与刘慈欣《流浪地球》的片段也被某常用论文检测工具判定其AI生成内容总体疑似度分别达到62.88%和52.88%。
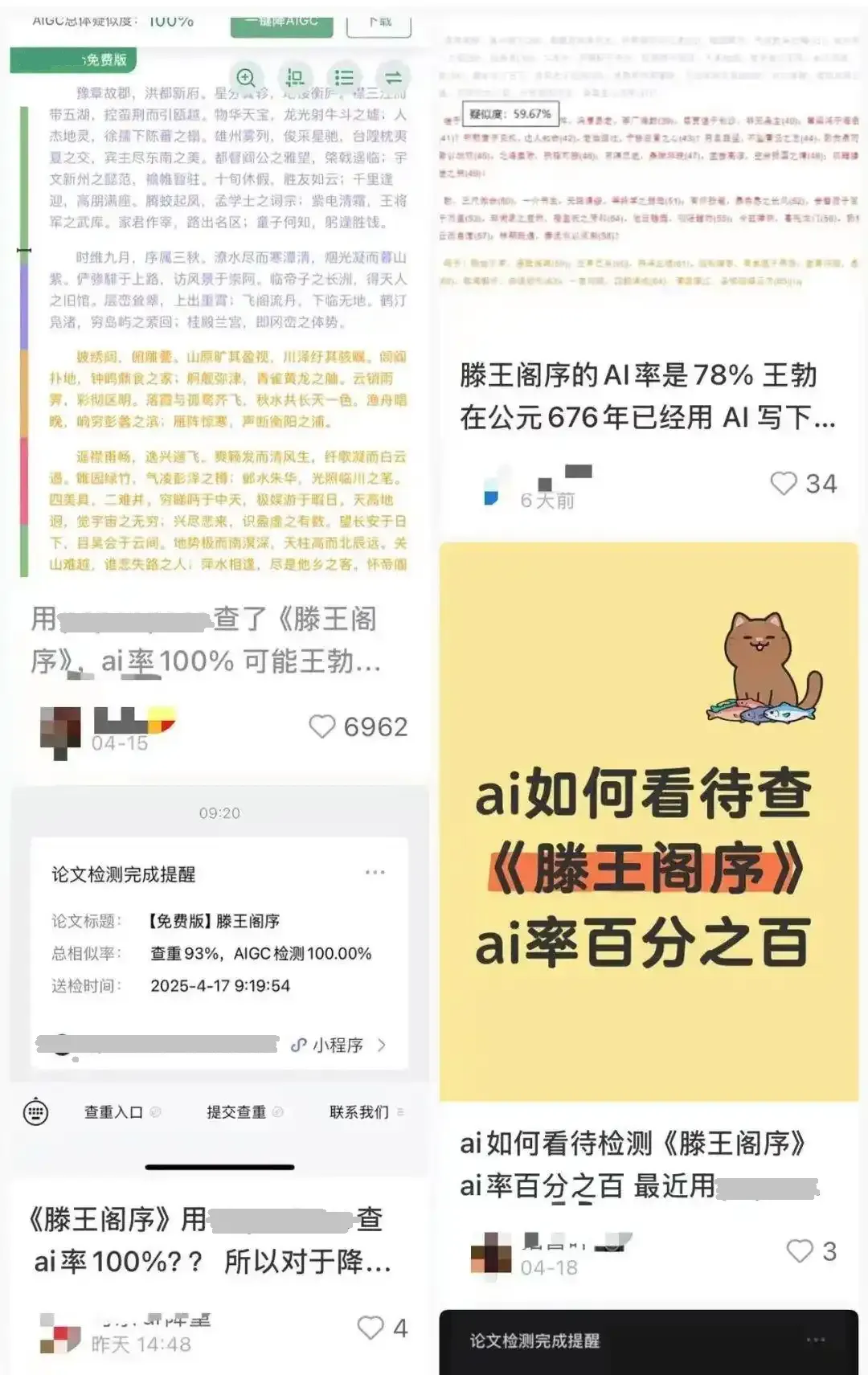
与此同时,网友还发现不同检测工具对同一篇文章的AI率检测结果也不一样,甚至同一工具对同一内容先后进行多次检测也可能出现差异值较大的结果。
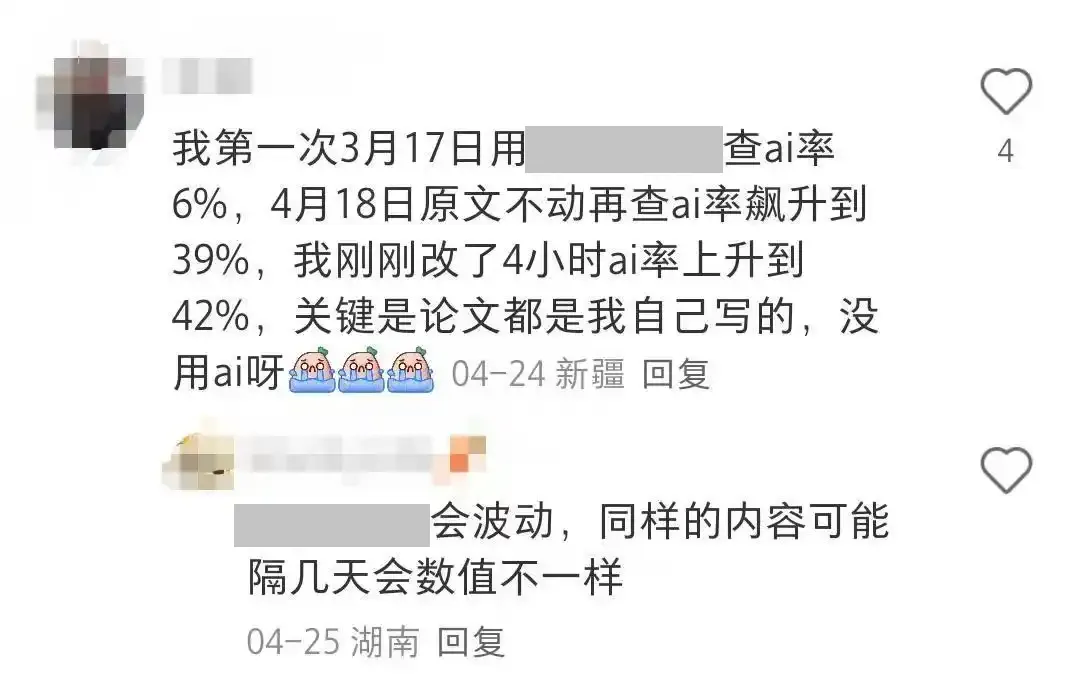
为什么不同检测工具或不同时段的同一个检测工具对同样的内容检测会出现迥异的结果?检测工具如何判定论文中的AI生成特征?目前又是否能通过技术手段让检测工具输出信度更高的检测结果?本文将对以上三个问题一一做出解答。
国内AIGC文本内容检测工具结果差异的原因
1、算法模型不同
当前常用的论文AI检测工具,有的是基于Transformer架构或于Bert架构,有的则是对传统机器学习算法进行了相应的改进。不同模型对文本特征的提取和识别能力都不尽相同,导致检测结果有一定差异,甚至不同的检测系统输出结果大相径庭。
2、特征选取不同
不同的检测工具模型在选取AIGC文本特征时各有侧重点。有的模型看重词汇丰富度和词频分布,有的则关注句子结构和语法复杂度。例如检测科技文献类AIGC文本的工具更加注重文章专业术语使用情况,它们和关注句子前后逻辑结构的工具就可能出现不同检测结果。即使选取相同的特征,工具对论文特征权重的分配也会有差异,例如文本连贯性等。
3、训练数据不同
训练数据的质量、规模以及所涉及行业领域的多样性,甚至数据格式都会影响检测效果。若模型在微调时的训练数据主要来自于特定的领域或时间段,或者是数量较少,那么对其他领域或新风格AIGC的检测能力就稍弱。比如,只用新闻领域的数据来训练检测工具,那么检测文学创作或学术论文的AIGC文本时准确性可能会降低。此外,数据通过不同标准的清洗、标注处理后,其数据的准确性和可靠性均不相同,检测结果也会不同。
另一方面,如果检测工具的训练数据更新不及时,赶不上AIGC的相关技术发展速度,就无法识别新的文章生成特征。如早期工具可能对新模型生成的文本的识别情况较差。
4、评估标准不同
针对目前大家应用工具得到的AIGC文本检测比,我们更倾向于将其理解为一种“类AI生成表达”的判断结果,即不定义是否有使用AI的行为,而是只基于技术判定某段文字是否有足够多的AI生成表达特征,为进一步判断论文质量、创新性等提供依据。
目前,国内尚未对AIGC文本检测做出具体的评估标准,各个检测工具只按照自身设定的指标和阈值进行判断。例如,有的工具将超过阈值0.9判断为AIGC内容;有的则是综合多个指标计算权重,超过一定权重的认为是AIGC生成文本。同时论文的人工审核环节也存在差异,主要受审核要求、审核人员的专业水平和经验的影响。建议在这一环节尽量避免使用AI生成比“一刀切”式审核处理,而是以引导理解如何正确使用AI工具为主,避免以检测论文关键创新部分是否不当使用AI工具为目的开展AI生成式检测审核。
AIGC生成内容“一眼假”的特征
1、语言特征
高频使用特定的词汇:如通篇文章中,频繁的出现表示逻辑关系的关联词(并列、承接、递进、选择及因果等词),连接词(表示时间、逻辑、举例、强调及总结等词)等各类特定词汇。
重复运用特定句式:如长句、复句、排比句等反复使用。
表达风格机械、刻意:行文风格要么通篇正式严谨,要么通篇随意松散,缺乏灵活的表现形式。
内容呼应不足:虽然文章表面看起来比较连贯,但在长文层面缺乏有效的呼应和衔接,相邻段落之间的过度不够自然,这反应了AIGC在内容组织方面的局限性。
2、内容特征
内容的创新性分析:AIGC生成的内容往往依赖已有的数据和模式,缺乏新颖独特的视角和创新性。它只能对已有的信息进行整合和罗列,难以提出新颖的观点和理论。
内容的逻辑性分析:AIGC生成的内容更加倾向于分点罗列的方式进行表达,而不是深层挖掘和分析,如不能对运算过程进行全面深入的分析总结、对未来结果或现象的预测不能提供足够的理由进行深入剖析等。
内容的偏差性分析:AIGC内容大多能够做到与主题高度契合,但缺乏人类创作中自然产生的人性化的主观表达和判断偏差,例如文章情感表达单一、人物塑造缺乏深度、缺乏人文关怀、不能体现地域文化特色、对社会现实关注不够等。
3、计算特征
字符频率计算:AIGC内容根据“预测下一个字符”机制生成,因此AIGC内容中每一个字符的频率往往都是上下文语境中的最优解,而人类撰写内容并不会严格遵循这一优选机制。
词汇搭配计算:AIGC内容会通过大规模参数训练计算词语共现概率,从而对紧邻搭配和远距离搭配进行优选,看似生动的内容背后都是最优搭配组合,而人类撰写内容则存在明显的搭配随机性和自然语言学习的自我理解性。
句子向量计算:在表层语言风格差异不明显的情况下,检测工具通过计算句子向量,可以找到区分AIGC内容和人类撰写内容在某个向量维度的最优区分阈值。
1: 1样本让模型判定不“跑偏”
首先需要承认的是,文察-AIGC检测模型没有加入文学作品素材进行训练,所以对文学作品进行检测的最终结果多少有点看脸。但是在避免为了检测工具提高AI生成识别率而发生矫枉过正的情况上,文察则有自己的独到之处。
在检测模型训练过程中,我们坚持AIGC训练样本和Human训练样本比例始终保持1: 1的原则,不同学科的训练样本比例也是1: 1,这样不会让模型有太强的AIGC判定倾向——假设在模型训练过程中,采用的所有训练样本都是AIGC生成文本,那么模型就会倾向于把大多数内容都判定为AIGC。这样检测工具在实测中虽然对AIGC内容的检测识别率会很高,但也会导致Human内容有很大概率被误判定为AIGC文本,反之亦然。
文察-AIGC检测业务将持续加强技术探索,以期为用户提供更科学、科学、准确的AI生成式检测服务。2025年5月6日,文察-AIGC检测模型已进行全面优化升级,升级后的模型能够支持更多热门模型生成内容,更好地识别主流AI工具生成的文本内容。
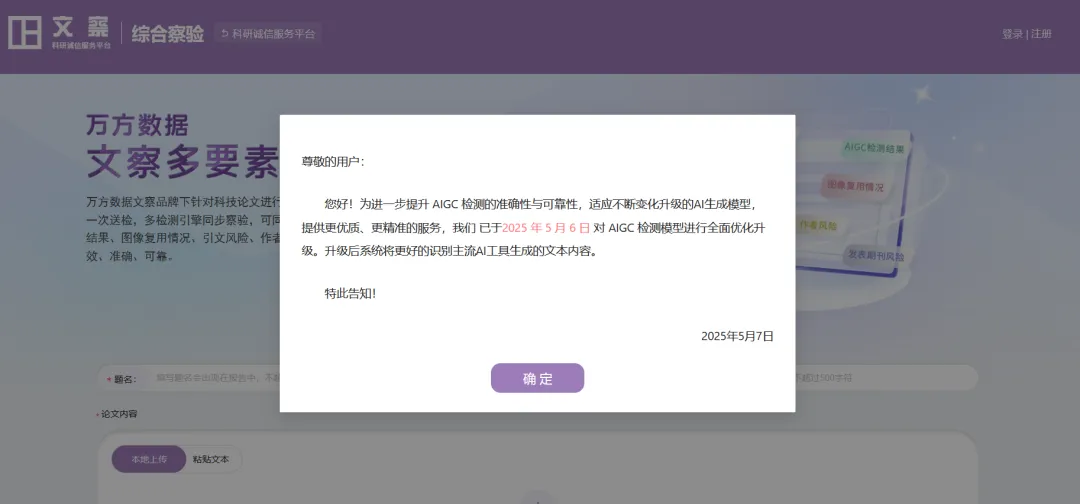
文察-AIGC检测系统入口:https://wencha.wanfangdata.com.cn/aigc
注:文中部分内容来源于网络










