
文本综合察验系统正式上线
https://wencha.wanfangdata.com.cn/text
随着人工智能的发展,AI生成内容冲击着学术生态,抄袭剽窃、AI代写、问题引用、用语失范等多重诚信风险给科研诚信建设带来了新的挑战...如何安全、高效、快速地对海量学术文本的诚信风险与质量问题进行管控?
破局利器!万方数据「文察」品牌重磅推出文本综合察验系统!一次送检,多维察验,为机构与学者提供文本检测新服务。
产品介绍
文本综合察验是万方数据文察品牌下针对科技论文进行文本的综合性诚信风险察验的工具。面向学术出版机构、高校、科研管理单位及有文本检测需求的个人,对文本进行多维度的诚信风险检测。 一次送检,可根据需求灵活匹配多个检测引擎同步察验,获得文本相似检测结果、AIGC检测结果、参考文献风险情况、用语规范风险检查结果,实现对论文的诚信风险、知识性差错、意识形态风险等全面把控。
一次检测,多维洞察
灵活组合,按需检测: 自由选择或组合四大核心检测维度
01 文本相似检测
检测送检论文文本内容是否与文本比对库内其他论文内容有相似或复用。
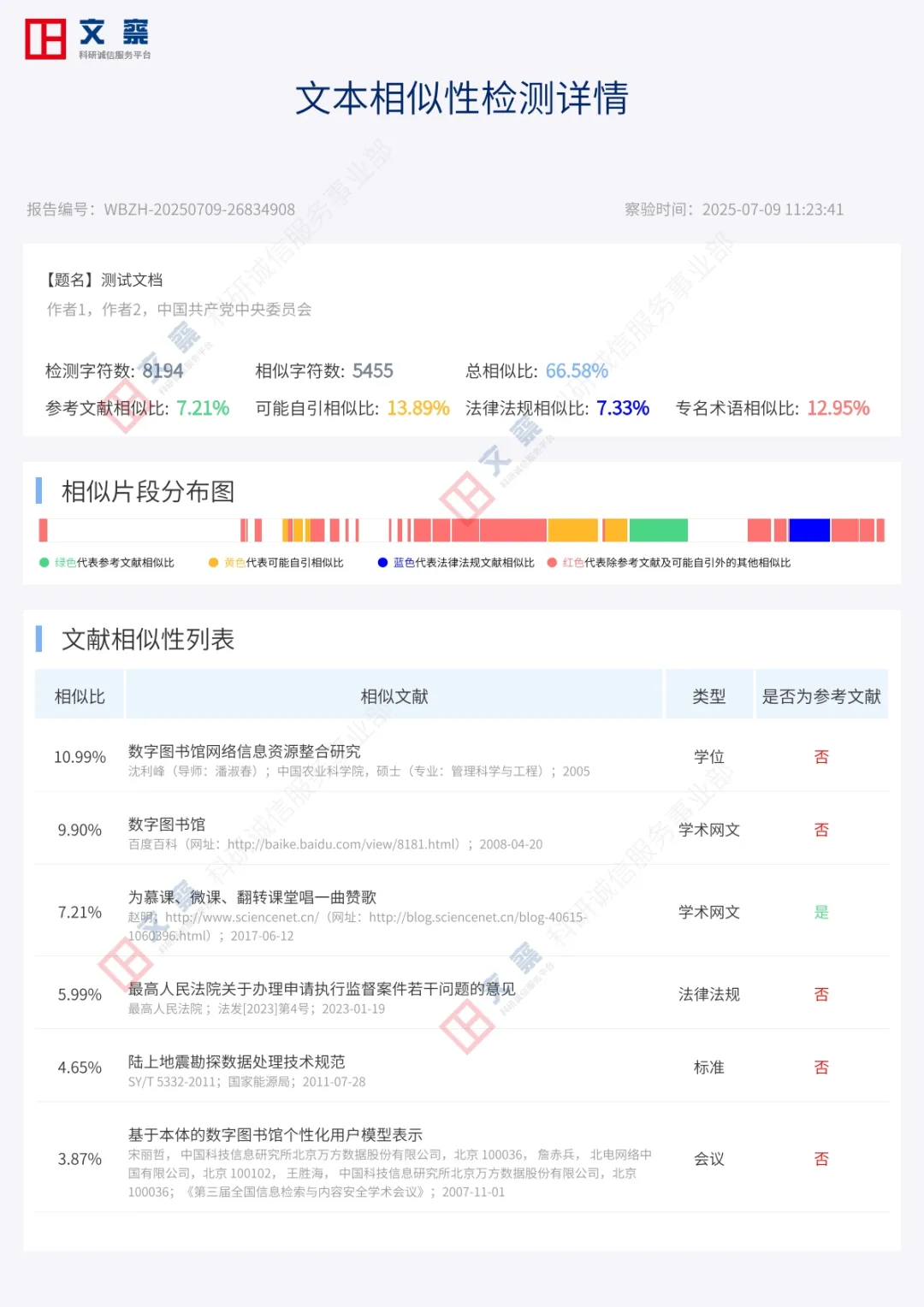
文本相似性检测详情报告可查看文本相似性指标、相似片段分布、相似文献列表及相似片段详情。
02 AIGC 检测
检测送检论文文本内容由AI大模型生成的内容比例及可能性。

AIGC检测详情报告可查看全文中疑似AI生成分布情况及全文疑似AI标注情况。
03 参考文献风险核查
检测送检论文识别到的参考文献是否有被撤稿、被学术质疑、被失信惩处公示、是否发表在警示期刊上。

参考文献风险核查详情报告可查看列出的参考文献是否存在撤稿、发表在警示期刊、学术质疑、失信惩处问题。
04 用语规范风险检查
检查送检论文文本内容中,是否存在用词用语通用错误(语病、字词错误、涉黄赌毒恐暴、不文明表述等)以及对问题用语(党政固定表达、重要讲话引用、党政敏感词、港澳台敏感词、国家部门名称、领导人姓名职务)的风险识别。
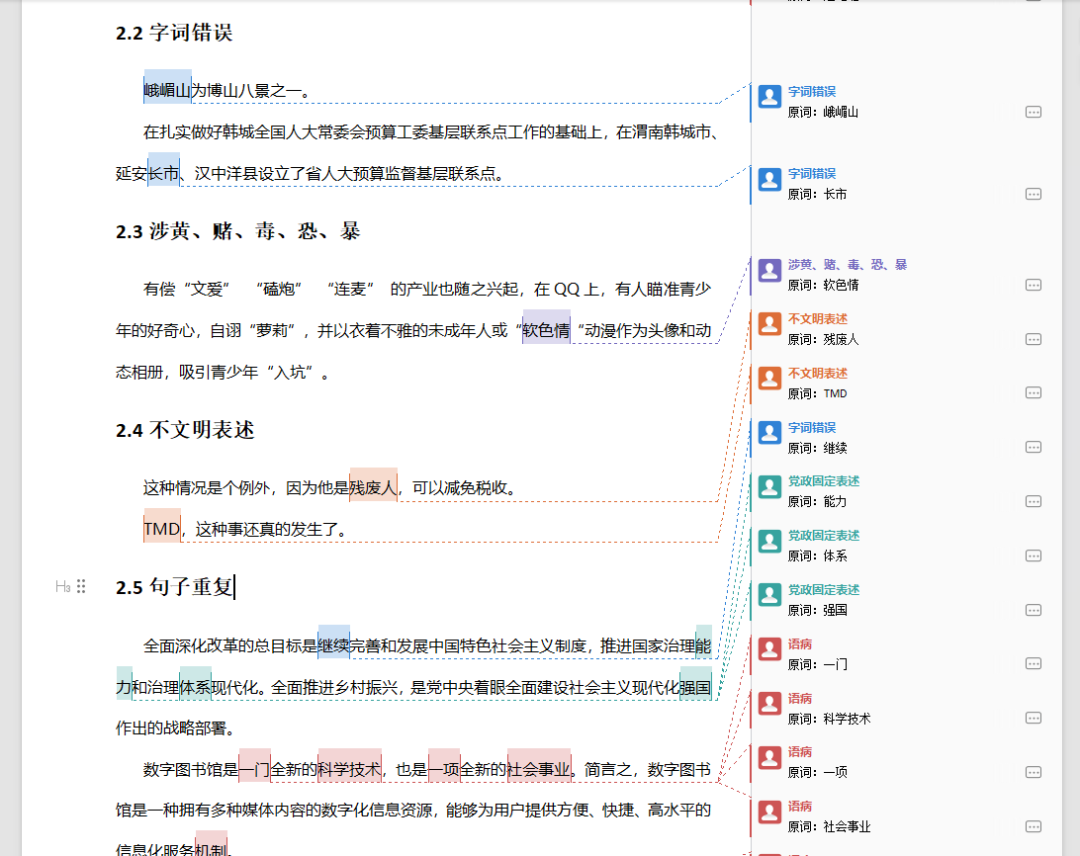
用语规范检查详情报告docx 格式

用语规范检查详情报告 pdf 格式
检测报告根据送检文献文件格式返回,如送检doc、docx格式文件,返回docx批注报告;送检pdf格式文件,返回pdf批注报告。
强大的数据底座
专业化聚合海量的文本比对资源、诚信风险信息,类别全、更新快
万方检测文本比对库
包括中国学术期刊数据库、国内外重要学术会议论文数据库、硕博士学位论文全文数据库、中国优秀报纸全文数据库、互联网学术资源数据库、中国专利全文数据库、特色英文文摘及全文数据库、中国标准全文数据库等中英文数据比对库共6.02亿篇。
科研诚信风险大数据资源
用于参考文献风险核查,涵盖包括中英文撤稿数据、发表后同行质疑信息、学术预警期刊数据、官方公开惩处信息等约529万,实时监测,持续性更新。
先进的技术模型
文本相似性检测算法
采用自主知识产权的全新相似度检测算法,基于海量比对库检测送检内容与比对库内文本相似度,检测高效精准、速度快。检测算法可支持多种检测功能应用,基于有效的文本预处理程序识别参考文献引用、自引等各类指标,算法支持中英文文本相似检测。
AIGC检测模型
选用注意力机制模型架构,结合预训练大语言(含大量学术文献)文本识别深度学习模型, 以及自然语言处理技术,利用神经网络的强大表达能力,判断人机生成文本之间的差异,从语言模式和语义逻辑对中文、英文、中文繁体及部分小语种进行深度分析,从而实现对大部分常见AI生成工具生产的内容的精准识别。
用语规范审查模型
基于人工智能大模型自然语言处理技术和“智能风控引擎”算法模型,采用大模型与小模型融合的审核机制,小模型负责初步判断和筛选错误,能够快速识别常见的字词错误和简单的语病问题。大模型则用于处理复杂、隐蔽的语义问题和逻辑错误,确保用语规范审查的准确性和深度。
如何进行文本内容检测
只需4步,轻松完成检测:
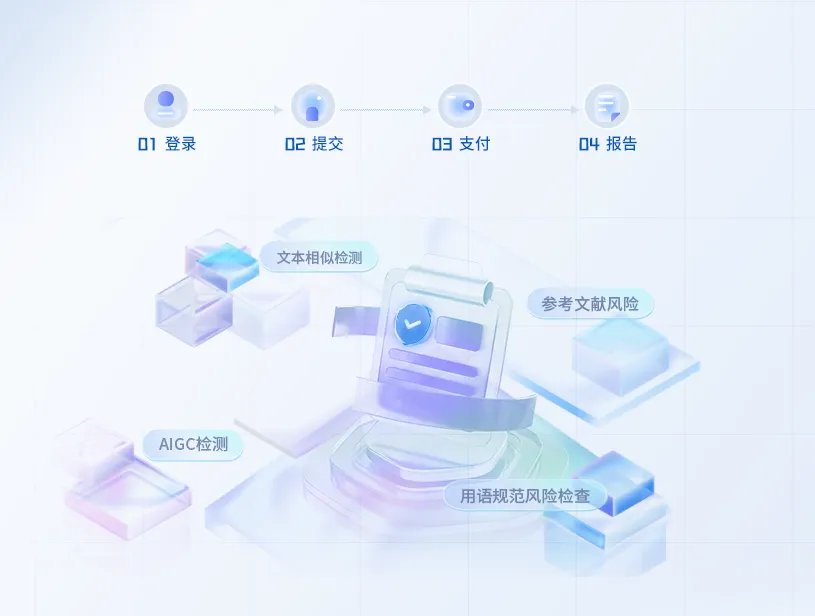
登录系统 访问网址: https://wencha.wanfangdata.com.cn/text
提交论文 支持单篇与批量送检;本地上传与手工录入等多种提交方式
支付订单 支持机构篇数支付与个人支付(支付宝、微信)等多种支付方式
获取报告 检测结果可筛选,检测信息可导出,检测进度易追踪,检测报告可下载










